Prompt Engineering学习——Prompt的构成
Prompt 的构成
一个完整的 Prompt 应该包含:清晰指示、相关上下文、有助理解的示例、明确输入以及期望输出格式。
角色(Character)
关键词:任务角色定义。
为 AI 设定最匹配任务的角色,例如“你是一位软件工程师”“你是一位小学老师”。指示(Instructions)
关键词:任务描述。
指示是对任务的明确描述,相当于给模型下命令,告诉模型应该做什么。上下文(Context)
关键词:背景信息。
上下文是与任务相关的背景信息,帮助模型理解当前任务环境。多轮交互中上下文尤其关键。例子(Examples)
关键词:示范学习。
提供一组(one-shot)或多组(few-shot)示例,演示任务执行方式与输出格式,通常能提升正确率。输入(Input)
关键词:数据输入。
输入是模型实际要处理的数据,应清晰标识,便于模型准确识别。输出(Output)
关键词:结果格式。
输出是模型生成结果。通常应约束格式,便于后续程序自动解析(如 JSON、XML)。
“定义角色”为什么有效?
其实一开始模型训练者并没有想过这有用,只是开“把ai当作人看”这个玩笑找到的规律。
但是由于传播的太广了导致现在的大模型训练数据充满了“角色定义”,所以就更加的有效了。
在这两个任务中,作者们都设计了一系列实验,以测试模型在处理长上下文时的性能。他们测试了不同的模型,包括BERT、RoBERTa、GPT-3等,并且也测试了不同长度的上下文,以了解上下文长度对模型性能的影响。
最终的结果采用Sebastian Raschka老师的一幅图展示: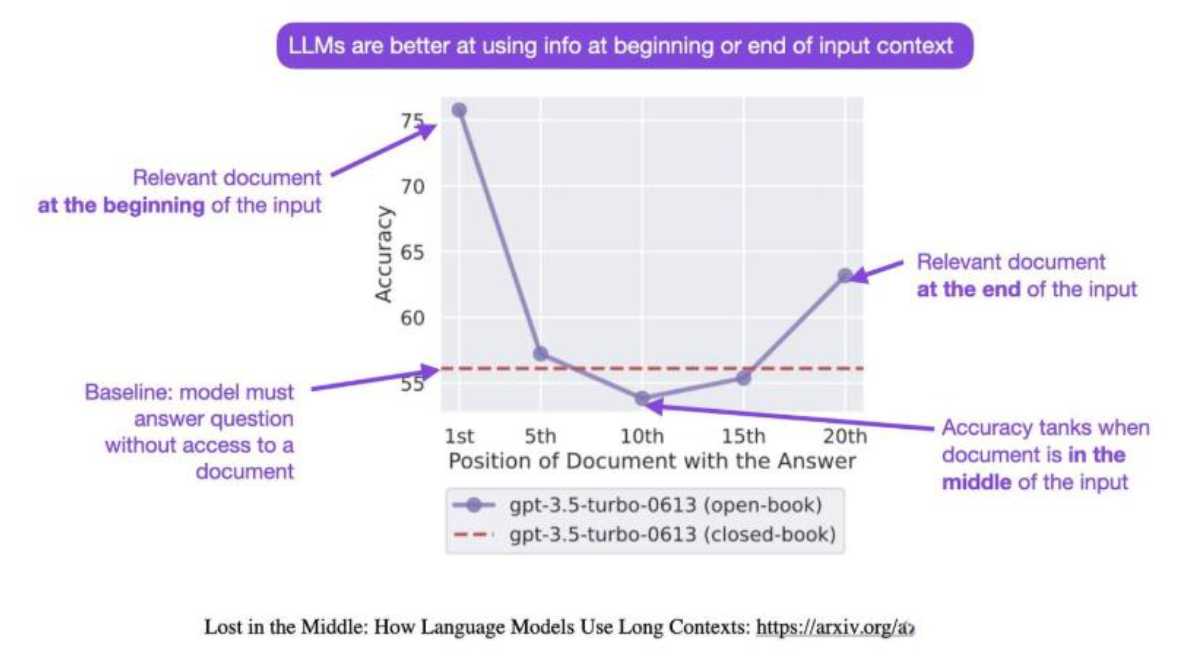
在大语言模型的输入上下文中改变相关信息的位置(即回答输入问题的段落的位置)会导致一个U形性能曲线——模型更擅长使用出现在输入上下文的开头或结尾的相关信息,而当模型需要访问和使用位于输入上下文中部的信息时,性能显著下降。例如,当将相关信息放置在输入上下文的中间时,GPT-3.5-Turbo在多文档问答任务上的开放式表现低于在没有任何文档的情况下的预测性能!也就是说,如果输入数据的重要信息没有出现在开始或者结尾位置,大模型可能会出现找不到答案的情况!
简单来说就是ai对于prompt的开头结尾更敏感!
先定义角色,就是在开头把问题域收窄,减少二义性。